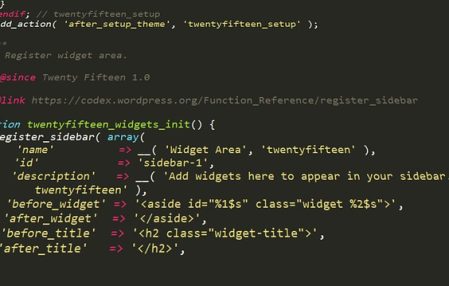
18 Feb #Database #Development #PL/SQL Start to Version your PL/SQL Application with Git by alukaszewski
08 Jan #Conferences #Database #Development #Oracle Forms #PL/SQL Conference: DOAG Forms Day 2018 21 in Berlin by alukaszewski
21 Nov #Development #Oracle Forms Boost your Forms Development with GIT and Forms API Master (DOAG 2017) by alukaszewski
30 Jul #Database #Development Install Oracle 11gR2 Express Edition on Ubuntu 14.04 (64-bit) by alukaszewski